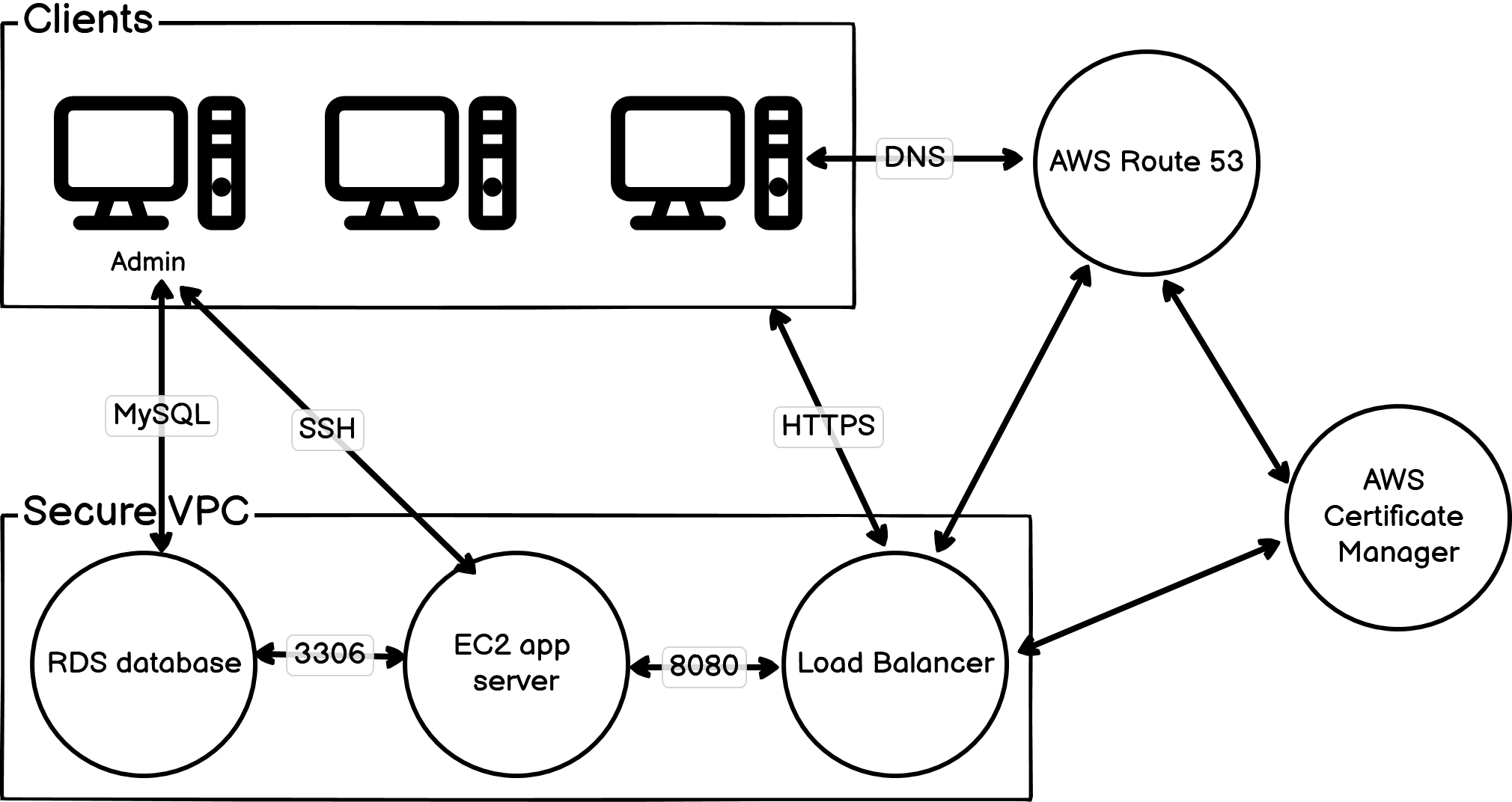
Zabbix is a very flexible infrastructure monitoring tool. Full manual is available here.
The central component of Zabbix is the server. You can find the installation instructions for Zabbix 6 on Ubuntu 22.04 LTS is available here, alternatively you can grab a pre-set up image from the download page.
The second crucial component of the Zabbix system is the Agent that provides the easiest and most flexible way for monitoring the servers. When downloading it, always use the latest version – agent2 in this case.
The configuration for Zabbix Agent is stored at /etc/zabbix/zabbix_agent2.conf
The minimal configuration for an Agent is as follows:
Server=127.0.0.1
ListenPort=10050
Hostname=apache
As you can probably guess, we configure the Zabbix server address, port, and client hostname. After the basics are configured, let’s enable the agent auto-start and make sure it picks up the config changes:
systemctl enable zabbix-agent2
systemctl restart zabbix-agent2
When that’s done, the agent is ready to be added via Zabbix GUI or auto-discovery (we’ll talk about it later).
The Hosts screen in Zabbix GUI allows you to:
- Monitor dozens of items at the same time – server load, RAM usage, service health (reference)
- Set up triggers for certain events (eg. /etc/paswd being modified), which can be used for notifications
- Set up graphs for visualising your data
- Manage discovery features (hardware – disks, partitions, network interfaces, software)
Templates in Zabbix vocabulary are pre-configured sets of features that are great for specific needs. Out of the box you can get fully-featured monitoring package for things like web servers, SSL certificates or other common use cases. Bear in mind that templates can contain conflicting item names, which could prevent you from using specific templates in some cases.
Monitoring custom scripts is relatively easy. Note that scripts are executed by the same user that handles Zabbix agent – usually that user is simply zabbix. After you create the script you want to monitor, edit the Agent config (/etc/zabbix/zabbix_agent2.conf) and define it at the bottom, following the pattern below:
UserParameter=apache_config_test, apachectl configtest
UserParameter=apache_status, systemctl status apache2.service | grep active
Remember to restart the Aagent with systemctl restart zabbix-agent2. Rest of the work is done via GUI in Hosts -> Items -> Create item. Just input the self-defined item name in the Key field, so Zabbix can pick it up.
No monitoring is serving it’s purpose without proper alerts in place. This is where Triggers come in. They usually come bundled with Templates, which makes them globally accessible. You can configure your own triggers easily, all the expected features are in place.
Notifications require some setup to work effectively. First step would be configuring the notification media. You can do that at Administration -> Media Types, where you can configure pre-defined media like Slack, Jira, Discord, SMS and many others. You can also define your own media types.
Second step is to visit Administration -> Users and configure user’s mediums – you need to set the email address, phone number and such.
Last step is customizing the trigger parameters at Configuration -> Actions -> Trigger.
Agent-less monitoring is exactly what the name says. You can monitor servers without agent installed. This limits the usefullnes of this feature, since we are limited mostly to monitoring services on open ports. We can use agent-less monitoring to check ping, SSL certificates, HTTP, TCP availability, HTTP APIs etc.
Automating host discovery is something very useful in production environment, especially where you auto-scale your infrastructure. Check it out at Configuration -> Actions -> Autoregistration actions. An example would be to accept all hosts with “Host meta data” value to set something specific (Like “webserver”), where you define two Operations:
- Add host – to simply link it to Zabbix
- Link to template – to attach specific monitoring package to given machine
Make sure you install and configure the Agent when you provision the new machine. The minimal per-server changes to zabbix_agent2.conf would be:
ServerActive=5.5.5.5 # Server IP
HostMetadata=webserver
As always, make sure to restart the Agent after making any config changes.
Discovering network services is something not very useful in my use cases. It can be used to scan network IP ranges for available services, like FTP, SSH, HTTP etc.